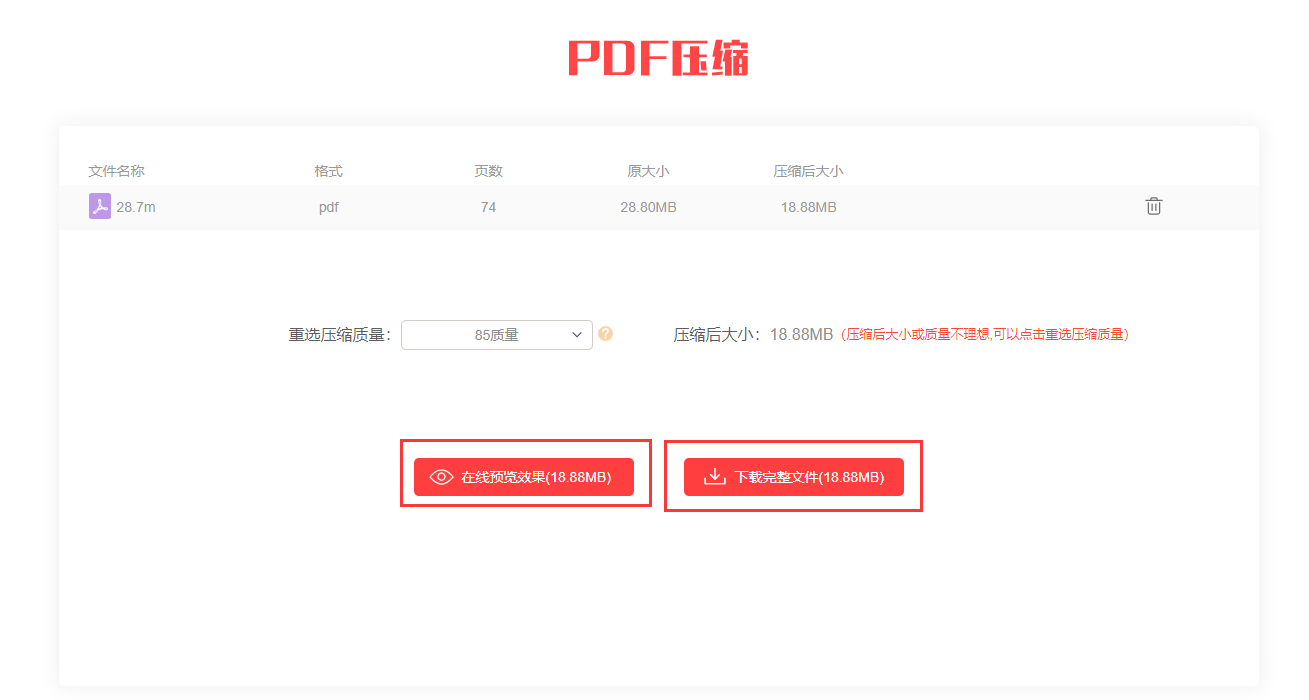
PostgreSQL删除重复数据同时保留每组中的一条记录
在 PostgreSQL 中,你不能直接从一个 CTE(公共表表达式)中删除数据,因为 CTE 只是一个临时的结果集,它并不直接对应一个可以更新的表。但是,你可以使用 CTE 来帮助识别哪些行需要被删除,然后在主查询中删除这些行。
示例
以下是一个正确的方法来删除重复的行,同时保留每组中的一条记录:
比如我有一张表my_table_name,里面有字段province和字段gnb_id,我想根据字段province和字段gnb_id分组,删除多余重复数据并保留一条
DELETE FROM my_table_name
WHERE ctid IN (
SELECT ctid
FROM (
SELECT
ctid,
ROW_NUMBER() OVER (PARTITION BY province, gnb_id ORDER BY gnb_id) AS rn
FROM
my_table_name
) sub
WHERE rn > 1
);
在这个查询中,我使用了 ctid 系统列(它是一个隐藏的列,用于标识表中的每一行)。ctid 可以被用来引用表中的特定行,并允许你在外部查询中删除它们。
子查询 sub 计算了每一组的行号,然后外部查询删除了所有行号大于 1 的行。注意,ctid 的使用依赖于 PostgreSQL 的内部实现,并且可能在某些情况下(如 VACUUM 操作后)发生变化。但是,在大多数情况下,使用 ctid 来删除行是安全且有效的。
如果你不希望或不能使用 ctid,你可以添加一个唯一的标识符列(比如 id),并在 DELETE 语句中使用这个列来识别要删除的行。但是,这需要你的表已经有一个这样的列。